
Map
本文为极客时间《Go语言核心36讲》的学习笔记,梳理了相关的知识点。
Map的简介
Map数据结构有多种多样的名称:哈希表,散列,字典,Map,键值对,这些都是广义上的Map数据类型。Map类型的数据结构在大多数的编程语言中都有支持,日常使用最多,面试最经常问到的是GO语言中的Map和Redis中的字典。
这是GO语言官方文档的描述:
Maps are a convenient and powerful built-in data structure that associate values of one type (the key) with values of another type (the element or value).
Map基本上是GO里面最经常,甚至所有技术组件,编程语言中最经常使用到的一个数据结构,它有一个显著的特点:
- 性能非常优秀。O(1)的复杂度。
- 通过键值对,可以实现一个元素与另一个元素的映射。
在实际使用中,我们可以用Map作为复杂数据的中间结构,进而实现多个数据的组合。
原理
Map的底层实现原理就是哈希(hash),它的用处非常广泛,我们后续的学习和工作中,会多次遇到。设计一个好的Map结构,必须要解决两个问题:
- 哈希函数
- 解决冲突
哈希函数
Hash算法的定义:将任意长度的二进制值转换为固定长度的二进制值。举个具体点的例子:MD5。甭管你的文件包多大,最后都能给你转成一个固定长度的字符串。我们最常用到的哈希算法:取模。 评估一个哈希函数的优劣,要看下它产出的结果是否足够的均匀分布。越是分布的不均匀,越容易出现哈希冲突,越是降低整体性能。
冲突解决
目前常用的哈希冲突方案有:开放寻址法和拉链法。我们简单介绍下:
开放寻址法
开放寻址法的底层是一个一维数组,当我们执行取模后,找到对应的位置,如果当前位置已经存在数据了,就顺序往后找到一个可以用的位置,把数据放进去。查询的时候也是同样的道理,找到位置后,进行一次键值比较,不一样的话就依次往后寻找,直到找到对应的值,或者发现一个空位置就返回。开放寻址法中对性能影响最大的是装载因子,它是数组中元素的数量与数组大小的比值
开放寻址的寻址方法也是可以优化的,可以详细读下复杂一点的寻址算法。
开放寻址法的好处是结构简单,缺点是如果数据塞得太多也就是装在因子过大,会严重降低性能。当装载因子等于1时,就相当于直面数组结构,完全失去了Map的意义。
拉链法
拉链法是最常用的解决冲突的办法,我们后续遇到的大多数Map场景都是通过拉链法解决的。相比开放寻址,拉链法的底层结构要复杂一些,在一维数组的基础上,增加了一层链表,或者你可以简单将其理解为二维数组。数组的第一维装哈希桶的编号,二维装同在一个桶内的数据。查询的时候先找到键值所在的桶,然后去逐个比较键值,找到桶内对应的数据。 理论上,为了保证性能,每个桶内的数据都在个位数。随着数据量增加,我们只需要扩容桶的数量就行。拉链法的优势:
- 实际存储地址,也就是桶内的存储空间,可以随用随取,降低开销。
- 可以通过扩容,降低数据量激增带来的性能损耗。
这里充分体现了计算机工程学的终极思想:如果一层中间件搞不定,那就再加一层。
引申,利用哈希冲突可以解决一些工程问题,可以看下布隆过滤器的原理。
使用技巧
键值对
Go语言的Map对于键值对是有要求的。我们之前提到过,GO语言里有值类型,引用类型等,有些类型是不能进行“==”操作的。对于Map而言,他的值类型,可以为任意类型,但是键类型是不允许出现函数类型,Map类型,切片类型的。
//正常操作
aMap := Map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
M1 := Map[struct{}]string{} //可以用,但最好别这样写。
M2 := Map[interface{}]string{} //可以用,但千万别这样写
//错误操作
//这三类编译器会直接报错,无效的映射键类型: 必须为键类型完全定义比较运算符 == 和 !=
M3 := Map[Map[string]int]int{}
M4 := Map[func()]int{}
M5 := Map[[]int]int{}为什么会出现这种情况? 就像我们上面说过的,hash算法是无法保证百分百不重复的,Go处理哈希冲突的时候,需要再拿着键的值来进行一轮比较,这时候就需要键值的类型必须要能够进行“==”操作。 我们再来完整的讲一遍GoMap查询一个数据是否存在的流程: 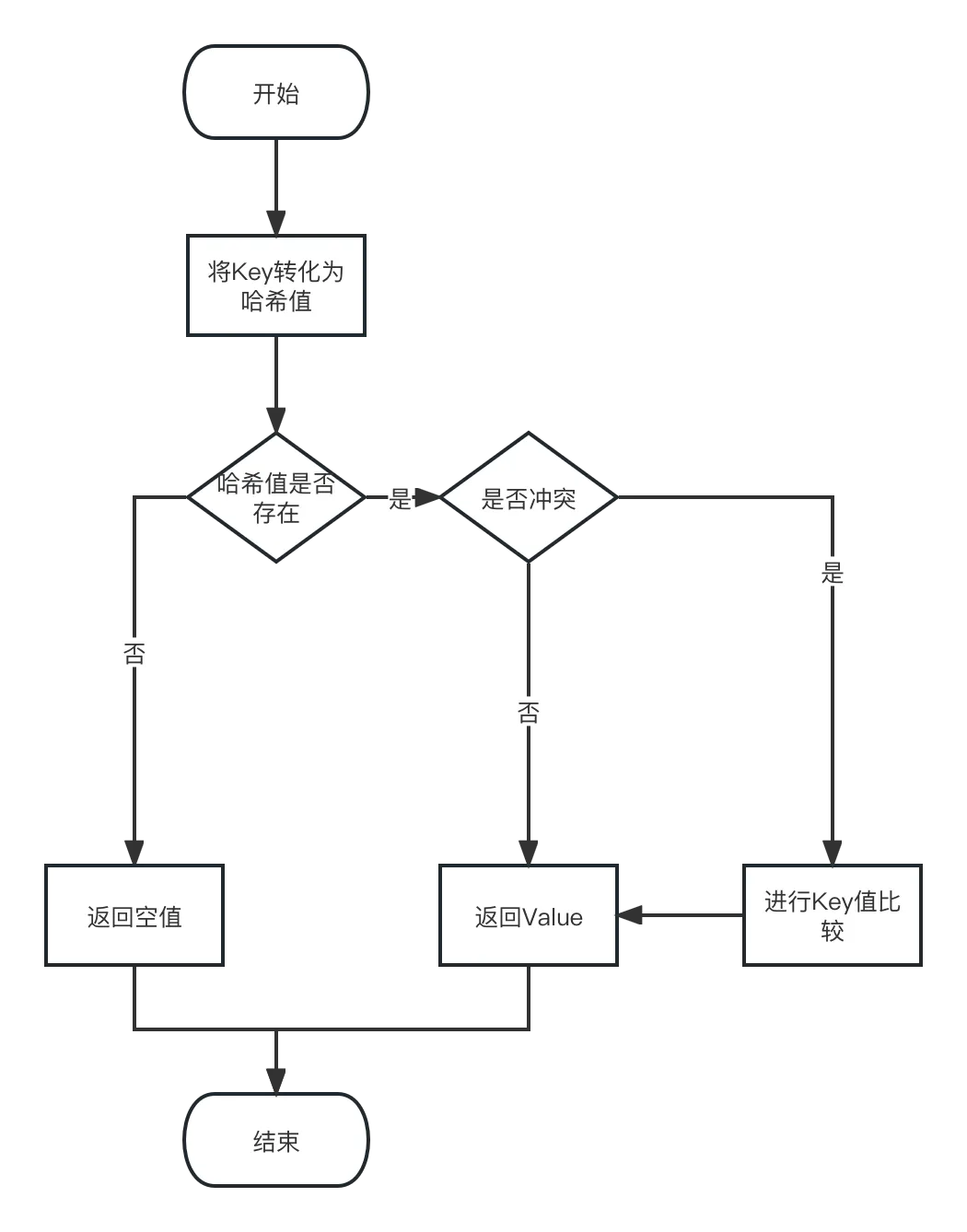
常用操作
声明
var M1 Map[string]int //不建议这样写
M2 := new(Map[string]int) //千万别这样写。gofmt会提示的
//以下方式都可以声明一个Map
M3:=Map[string]int{}
M4 := make(Map[string]int) //这是比较推荐的方式。
//声明好后可以直接用,不会有任何问题。
a := M3["str"]
delete(M3,"str")
M3["str"] = 1
a = M3["str"]
//M1 要单独说一下
a := M1["str"]
delete(M1,"str")
M1["str"] = 1 //这里会报panic
a = M1["str"]也就是说,按照我们推荐的方式声明一个Map,读写操作不会有任何问题。但是操作一个值为nil的Map时,读操作,删除操作都不会有问题,写操作会Panic。
使用
直接看代码:
M1 := make(Map[string]int)
//M1["str"] = 1
value,ok := M1["str"]// value 默认为Map 定义的值,ok 固定位 bool 值
if ok {
fmt.Printf("str:%d",value)
}
//可以合并:
if value,ok := M1["str"];ok {
//注意此处 value ok 的作用域
fmt.Printf("str:%d",value)
}遍历
GoMap的遍历是随机的,无序的,在使用时一定要注意!
M1 := make(Map[int]int)
//正序塞入数据
M1[1] = 1
M1[2] = 2
M1[3] = 3
M1[4] = 4
M1[5] = 5
for k, v := range M1 {
fmt.Println("key:%d,value:%d",k,v) //不是每一次都是排好序的
}引申,为什么Map的循环访问会出现乱序的情况?循环Map时,会从一个随机的位置开始。详情可以去看源码。
如何实现Map的有序访问?
- 使用切片,将Key先排好序,再遍历逐个去Map中取Value。
- 包装一个新的数据结构。链表,或者其他结构。
Map的底层设计
详情大家可以直接看最后的引申阅读,我这里只讲下我的阅读笔记:
- 在Map的实现中,哈希的低位用来参与计算桶的编号,高8位会冗余一份存在桶内,用来加快比较。
- 两个状态下会发生扩容:装载因子超过6.5;使用了大量的溢出桶。
- 每个桶里只能存8个KV对,超过这个数量会分配在溢出桶内。
第一条非常具有参考价值。我在工作中经常会用这个方法来解决实际中的工程问题:比如记录用户信息和设备信息之间的对应关系。
问题引申
如何安全的使用Map?
Map本身是不安全的,非原子操作的。多个GoRoutine并发操作Map轻则数据混乱,重则直接panic。如果要在并发中使用Map,要么自己加读写锁sync.RWMutex,要么使用sync.Map。
应该优先考虑哪些类型作为字典的键类型?
原则上讲:求哈希和判等操作的速度越快,对应的类型就越适合作为键类型。 具体而言:优先选用数值类型和指针类型,其次使用长度固定的字符串,最好不要用高级类型(数组,结构体,接口等)除了效率比较低,还容易引发其他问题。
Go语言中的Map如何扩容?
扩容的时机:装载因子超过一定的阈值或者使用了太多的溢出桶时。 扩容的规则:
- 等量扩容
使用溢出桶太多的时候会进行等量扩容。申请和原来等量的内容,将原来的数据重新整理后,写入到新的内存中。可以简单的认为是一次内存整理,目的是提高查询效率。
引申,如果没有等量扩容会出现什么问题?随着溢出桶缓慢增长,有内存溢出的风险。
- 增量扩容
分成两步: 第一步进入扩容状态,先申请一块新的内存,翻倍增加桶的数量,此时buckets指向新分配的桶,oldbuckets指向原来的桶。 第二步,重新计算老的桶中的哈希值在新的桶内的位置(取模或者位操作),将旧数据用渐进式的方式拷贝到新的桶中。 渐进式迁移分两块,一方面会从第一个桶开始,顺序迁移每一个桶,如果下一个桶已经迁移,则跳过。另一方面,当我们操作某一个桶的元素时,会迁移两个桶,进而保证经过一些操作后一定能够完成迁移。 当我们访问一个正在迁移的Map时,如果存在oldbuckets,那么直接去中oldbuckets寻找数据。当我们遍历一个正在迁移的Map时,新的和旧的就会遍历,如果一个旧的的桶已经迁移走了,那么就直接跳过,反正不在旧的就在新的里。Map遍历本身就是无序的。